MLA-C01 Detailed Answers & Valid MLA-C01 Test Review
Wiki Article
P.S. Free & New MLA-C01 dumps are available on Google Drive shared by RealExamFree: https://drive.google.com/open?id=1BtZDxwRuBks5nAplSbitdOCiTQy6gVRp
With the rise of internet and the advent of knowledge age, mastering knowledge about computer is of great importance. This MLA-C01 exam is your excellent chance to master more useful knowledge of it. Up to now, No one has questioned the quality of our MLA-C01 training materials, for their passing rate has reached up to 98 to 100 percent. Our AWS Certified Associate study dumps are priced reasonably so we made a balance between delivering satisfaction to customers and doing our own jobs. So in this critical moment, our MLA-C01 real materials will make you satisfied. Our MLA-C01 exam materials can provide integrated functions. You can learn a great deal of knowledge and get the certificate of the exam at one order like win-win outcome at one try.
Amazon MLA-C01 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
>> MLA-C01 Detailed Answers <<
Valid MLA-C01 Test Review - MLA-C01 Latest Braindumps Files
Our products are compiled by experts from various industries and they are based on the true problems of the past years and the development trend of the industry. What's more, according to the development of the time, we will send the updated materials of MLA-C01 test prep to the customers soon if we update the products. Under the guidance of our study materials, you can gain unexpected knowledge. Finally, you will pass the exam and get a MLA-C01 Certification. Customers can learn according to their actual situation and it is flexible. Next I will introduce the advantages of our MLA-C01 test prep so that you can enjoy our products.
Amazon AWS Certified Machine Learning Engineer - Associate Sample Questions (Q98-Q103):
NEW QUESTION # 98
An ML engineer wants to use a set of survey responses as training data for an ML classifier. All the survey responses are either "yes" or "no." The ML engineer needs to convert the responses into a feature that will produce better model training results. The ML engineer must not increase the dimensionality of the dataset.
Which methods will meet these requirements? (Choose two.)
- A. One-hot encoding
- B. Tokenization
- C. Binary encoding
- D. Statistical imputation
- E. Label encoding
Answer: C,E
Explanation:
Both binary encoding and label encoding convert categorical yes/no responses into numerical values without increasing dimensionality. For example, mapping yes → 1 and no → 0. Unlike one-hot encoding, which would add extra dimensions, these methods keep the dataset compact and effective for training.
NEW QUESTION # 99
A company has multiple models that are hosted on Amazon SageMaker Al. The models need to be re-trained.
The requirements for each model are different, so the company needs to choose different deployment strategies to transfer all requests to a new model.
Select the correct strategy from the following list for each requirement. Select each strategy one time. (Select THREE.)
. Canary traffic shifting
. Linear traffic shifting guardrail
. All at once traffic shifting
Answer:
Explanation:
Explanation:
1## Simultaneous calls to the endpoint must reach models with the same configuration Correct strategy: All at once traffic shifting Why:
"All at once" replaces the old model with the new model immediately. After the switch, all concurrent requests hit only the new model configuration, guaranteeing configuration consistency across simultaneous calls.
2## The new model must receive only a fraction of the requests for validation before receiving all the traffic Correct strategy: Canary traffic shifting Why:
Canary deployments route a small percentage of traffic (for example, 5% or 10%) to the new model first. This allows validation of correctness and performance before shifting 100% of traffic.
3## Traffic to the new model must increase gradually to ensure that pipelines that rely on the endpoint do not fail because of changes in latency Correct strategy: Linear traffic shifting guardrail Why:
Linear traffic shifting gradually increases traffic in equal increments over time and includes guardrails (such as CloudWatch alarms) to automatically roll back if latency or errors exceed thresholds.
NEW QUESTION # 100
A company is developing an ML model for a customer. The training data is stored in an Amazon S3 bucket in the customer ' s AWS account (Account A). The company runs Amazon SageMaker AI training jobs in a separate AWS account (Account B).
The company defines an S3 bucket policy and an IAM policy to allow reads to the S3 bucket.
Which additional steps will meet the cross-account access requirement?
- A. Create the S3 bucket policy in Account A. Attach the IAM policy to an IAM role that SageMaker AI uses in Account B.
- B. Create the S3 bucket policy in Account B. Attach the IAM policy to an IAM role that SageMaker AI uses in Account B.
- C. Create the S3 bucket policy in Account A. Attach the IAM policy to an IAM role that SageMaker AI uses in Account A.
- D. Create the S3 bucket policy in Account B. Attach the IAM policy to an IAM role that SageMaker AI uses in Account A.
Answer: A
Explanation:
For cross-account Amazon S3 access, AWS requires two components:
An S3 bucket policy in the owning account (Account A) that grants access to a principal in another account An IAM role policy in the consuming account (Account B) that allows the service to access the bucket Amazon SageMaker training jobs assume an IAM role in the account where the job runs-in this case, Account B. Therefore, the IAM policy must be attached to the SageMaker execution role in Account B.
The S3 bucket policy must reside in Account A because bucket policies are owned and enforced by the bucket owner. This policy explicitly allows the IAM role from Account B to read the training data.
Any other combination fails either because the policy is in the wrong account or because the role is not the one used by SageMaker.
AWS documentation clearly describes this pattern as the correct way to grant cross-account access for SageMaker training jobs.
Therefore, Option B is the correct and AWS-aligned solution.
NEW QUESTION # 101
An ML engineer is building a generative AI application on Amazon Bedrock by using large language models (LLMs).
Select the correct generative AI term from the following list for each description. Each term should be selected one time or not at all. (Select three.)
* Embedding
* Retrieval Augmented Generation (RAG)
* Temperature
* Token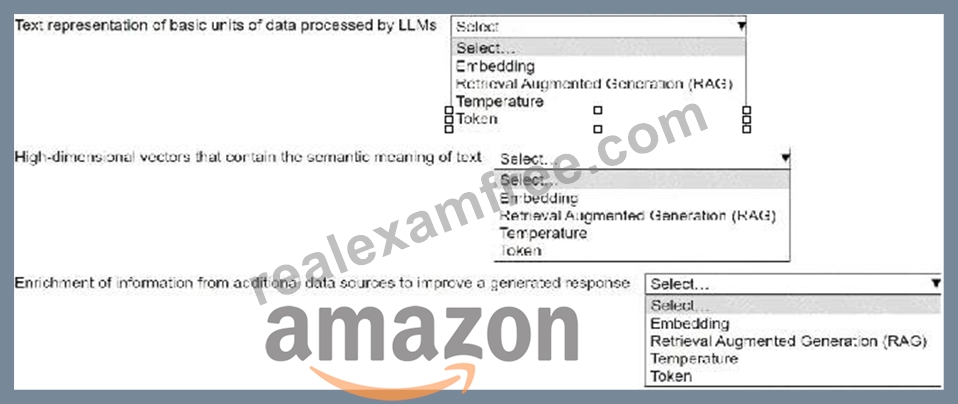
Answer:
Explanation: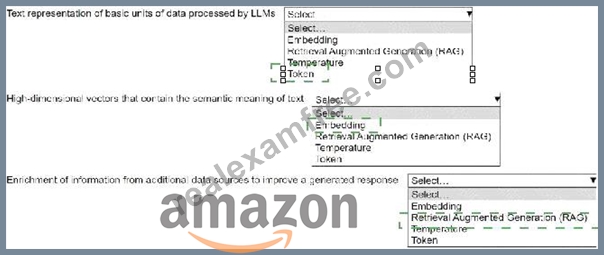
Explanation:
* Text representation of basic units of data processed by LLMs:Token
* High-dimensional vectors that contain the semantic meaning of text:Embedding
* Enrichment of information from additional data sources to improve a generated response:
Retrieval Augmented Generation (RAG)
Comprehensive Detailed Explanation
* Token:
* Description: A token represents the smallest unit of text (e.g., a word or part of a word) that an LLM processes. For example, "running" might be split into two tokens: "run" and "ing."
* Why?Tokens are the fundamental building blocks for LLM input and output processing, ensuring that the model can understand and generate text efficiently.
* Embedding:
* Description: High-dimensional vectors that encode the semantic meaning of text. These vectors are representations of words, sentences, or even paragraphs in a way that reflects their relationships and meaning.
* Why?Embeddings are essential for enabling similarity search, clustering, or any task requiring semantic understanding. They allow the model to "understand" text contextually.
* Retrieval Augmented Generation (RAG):
* Description: A technique where information is enriched or retrieved from external data sources (e.g., knowledge bases or document stores) to improve the accuracy and relevance of a model's generated responses.
* Why?RAG enhances the generative capabilities of LLMs by grounding their responses in factual and up-to-date information, reducing hallucinations in generated text.
By matching these terms to their respective descriptions, the ML engineer can effectively leverage these concepts to build robust and contextually aware generative AI applications on Amazon Bedrock.
NEW QUESTION # 102
An ML engineer wants to re-train an XGBoost model at the end of each month. A data team prepares the training data. The training dataset is a few hundred megabytes in size. When the data is ready, the data team stores the data as a new file in an Amazon S3 bucket.
The ML engineer needs a solution to automate this pipeline. The solution must register the new model version in Amazon SageMaker Model Registry within 24 hours.
Which solution will meet these requirements?
- A. Create an S3 Lifecycle rule to start the pipeline every time a new object is uploaded to the S3 bucket.
- B. Create an Amazon CloudWatch rule that runs on a schedule to start the pipeline every 30 days.
- C. Create an Amazon EventBridge rule to start an AWS Step Functions TrainingStep every time a new object is uploaded to the S3 bucket.
- D. Create an AWS Lambda function that runs one time each week to poll the S3 bucket for new files.
Invoke the Lambda function asynchronously. Configure the Lambda function to start the pipeline if the function detects new data.
Answer: C
Explanation:
The requirement is event-driven automation when new data arrives in Amazon S3, followed by training and model registration. Amazon EventBridge natively supports S3 object creation events and can trigger downstream workflows immediately.
By using EventBridge to start an AWS Step Functions workflow that includes a training step and a SageMaker Model Registry registration step, the pipeline runs automatically as soon as new data is uploaded-well within the 24-hour requirement.
Option A introduces unnecessary polling and delay. Option B is time-based and does not ensure alignment with data readiness. Option C is invalid because S3 Lifecycle rules manage object transitions, not workflow execution.
Therefore, EventBridge-triggered Step Functions is the correct solution.
NEW QUESTION # 103
......
As old saying goes, god will help those who help themselves. So you must keep inspiring yourself no matter what happens. At present, our MLA-C01 exam materials are able to motivate you a lot. Our products will help you overcome your laziness. And you will become what you want to be with the help of our MLA-C01 learning questions. You can realize and reach your dream. Also, you will have a pleasant learning of our MLA-C01 study quiz.
Valid MLA-C01 Test Review: https://www.realexamfree.com/MLA-C01-real-exam-dumps.html
- Pass Guaranteed Amazon MLA-C01 - First-grade AWS Certified Machine Learning Engineer - Associate Detailed Answers ???? Search for ➽ MLA-C01 ???? and obtain a free download on [ www.exam4labs.com ] ✊MLA-C01 Reliable Exam Pattern
- Pass Guaranteed 2026 MLA-C01: AWS Certified Machine Learning Engineer - Associate –The Best Detailed Answers ???? Search for ✔ MLA-C01 ️✔️ and easily obtain a free download on ⮆ www.pdfvce.com ⮄ ????Exam MLA-C01 Review
- MLA-C01 Latest Braindumps Pdf ???? MLA-C01 Boot Camp ???? MLA-C01 Study Material ???? Download ☀ MLA-C01 ️☀️ for free by simply entering ⏩ www.prepawaypdf.com ⏪ website ????MLA-C01 Online Tests
- Exam MLA-C01 Review ???? MLA-C01 Latest Braindumps Pdf ???? MLA-C01 Valid Real Exam ???? Easily obtain free download of ⇛ MLA-C01 ⇚ by searching on [ www.pdfvce.com ] ▶Valid MLA-C01 Real Test
- Reliable MLA-C01 Practice Questions ???? MLA-C01 Free Practice Exams ???? MLA-C01 Latest Braindumps Book ???? Search for 《 MLA-C01 》 on ➡ www.exam4labs.com ️⬅️ immediately to obtain a free download ????Latest MLA-C01 Practice Materials
- Valid MLA-C01 Real Test ???? MLA-C01 Reliable Test Tutorial ➡️ MLA-C01 Reliable Test Tutorial ???? Simply search for ✔ MLA-C01 ️✔️ for free download on ( www.pdfvce.com ) ????MLA-C01 Latest Braindumps Pdf
- Reliable MLA-C01 Practice Questions ⛅ Exam MLA-C01 Review ???? New MLA-C01 Exam Price ???? The page for free download of ⮆ MLA-C01 ⮄ on ⏩ www.exam4labs.com ⏪ will open immediately ????MLA-C01 Pdf Format
- TOP MLA-C01 Detailed Answers 100% Pass | High-quality Valid AWS Certified Machine Learning Engineer - Associate Test Review Pass for sure ???? Open ➠ www.pdfvce.com ???? and search for 【 MLA-C01 】 to download exam materials for free ????Latest MLA-C01 Exam Cost
- MLA-C01 Study Material ???? Latest MLA-C01 Exam Cost ???? MLA-C01 Free Practice Exams ???? Open website ▶ www.prepawayete.com ◀ and search for [ MLA-C01 ] for free download ????MLA-C01 Latest Braindumps Pdf
- MLA-C01 Test Torrent ???? Copy URL [ www.pdfvce.com ] open and search for “ MLA-C01 ” to download for free ????MLA-C01 Boot Camp
- Pass Guaranteed Quiz 2026 Unparalleled MLA-C01: AWS Certified Machine Learning Engineer - Associate Detailed Answers ☂ Search for ▷ MLA-C01 ◁ on ▷ www.vce4dumps.com ◁ immediately to obtain a free download ????MLA-C01 Reliable Test Tutorial
- jonasqwgn067886.plpwiki.com, ebiz-directory.com, ellattro570314.blog2freedom.com, janiceaqyv431009.thenerdsblog.com, myauwxz214103.blog2freedom.com, albieybbc740317.wikiconverse.com, marciltx539450.theisblog.com, sahiloikj511716.mycoolwiki.com, kathrynwuvp498668.topbloghub.com, laytnfrjf727431.wizzardsblog.com, Disposable vapes
P.S. Free 2026 Amazon MLA-C01 dumps are available on Google Drive shared by RealExamFree: https://drive.google.com/open?id=1BtZDxwRuBks5nAplSbitdOCiTQy6gVRp
Report this wiki page